Please click the thumbnails of posters to see the full-sized posters.
Poster 1. A Novel Correlation based Co-localization Analysis of Super-resolution Images
Xueyan Liu
University of New Orleans
Email: xliu10@uno.edu
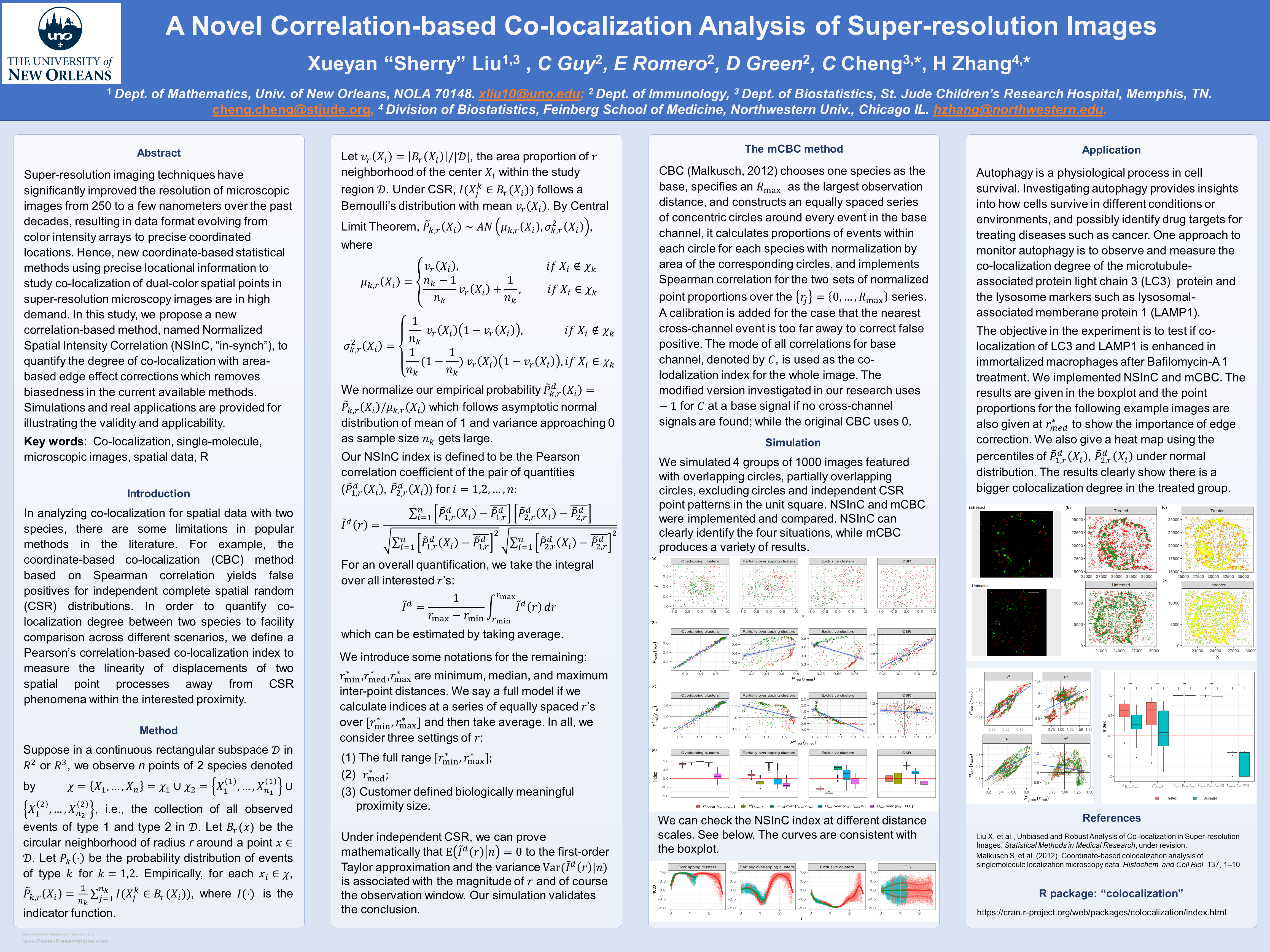
Abstract: Super resolution imaging techniques have significantly improved the resolution of microscopic images from 250 to a few nanometers over the past decades, resulting in data format evolving from color intensity arrays to precise coordinated locations. Hence, new coordinate based statistical methods using precise locational information to study co localization of dual color spatial points in super resolution microscopy images are in high demand. In this study, we propose a new correlation based method, named Normalized Spatial Intensity Correlation ( NSInC , “in synch”), to quantify the degree of co localization with area based edge effect corrections which removes biasedness in the current available methods. Simulations and real applications are provided for illustrating the validity and applicability.
Poster 2. Combining Batches of High-Dimensional Multiplexed Images
Coleman Harris
Vanderbilt University
Email: coleman.r.harris@vanderbilt.edu
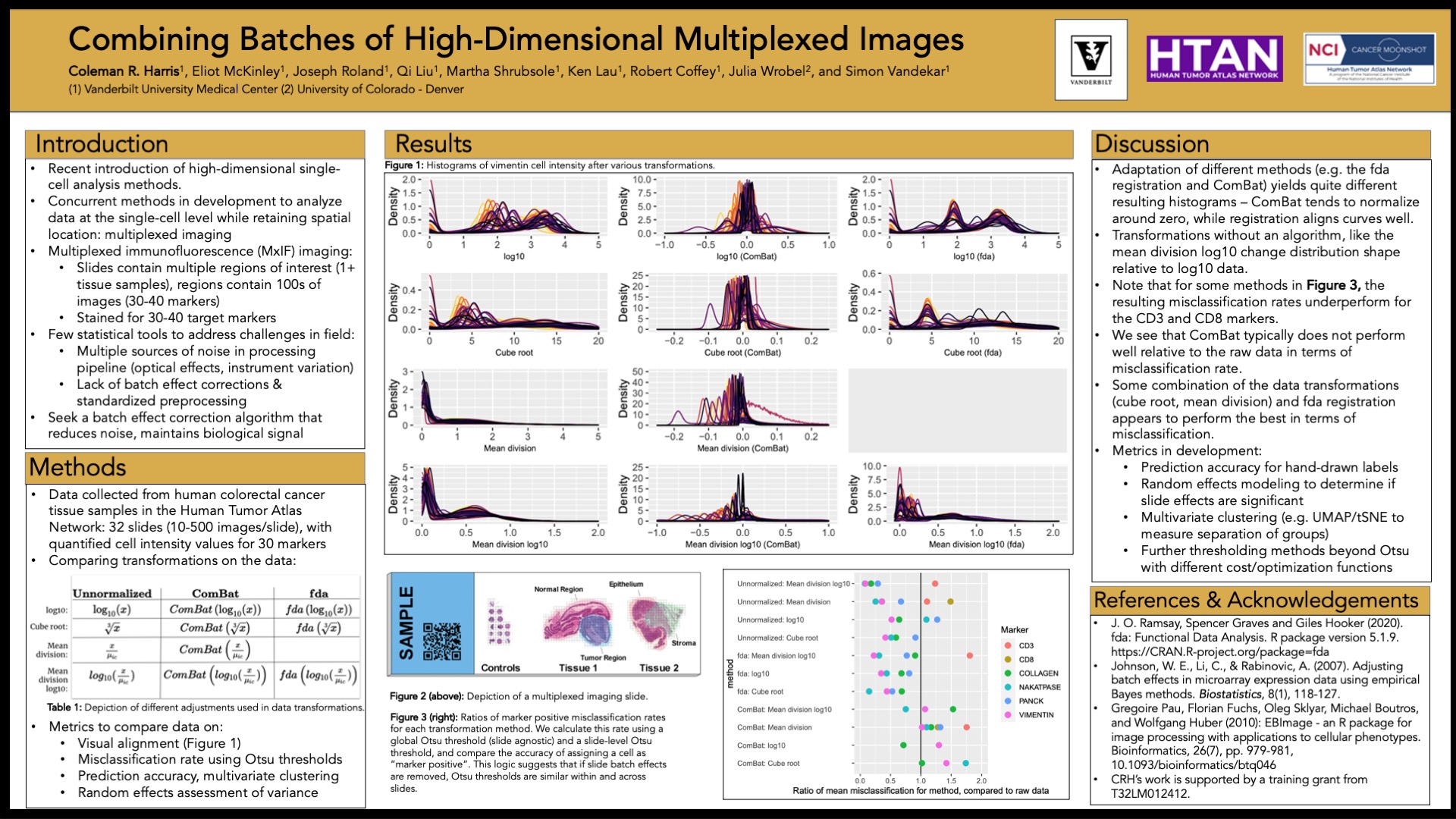
Abstract: High-dimensional multiplexed imaging methods can help quantify the heterogeneity of cell populations in healthy and tumorous tissues, offering insight into tumor progression and improved treatment strategies. However, implicit biases exist in the imaging pipeline - images are distorted by optical effects, slide and batch effects, and instrument variability. Normalization of this data is compounded by the number of markers and natural tissue variability within each image, introducing systematic differences that impact inference. In this work, we introduce an image normalization pipeline to reduce systematic variability in multiplexed images by correcting for batch effects. We build on existing methods to compare the following approaches to correct for the batch effects in the data: a logarithmic transformation, a simple standardization (division by the mean), and approaches that adapt ComBat and functional data registration. We demonstrate these methods by analyzing multiplexed immunofluorescence (MxIF) images of human colorectal tissue samples to quantify the reduction in variability of the data, namely using thresholding methods and random effects models. We further demonstrate the method's ability to retain biological signal by evaluating prediction accuracy of models for specific regions containing tumors in the tissue samples.
Poster 3. PPA: Principal Parcellation Analysis for Brain Connectomes and Multiple Traits
Rongjie Liu
Florida State University
Email: rliu3@fsu.edu
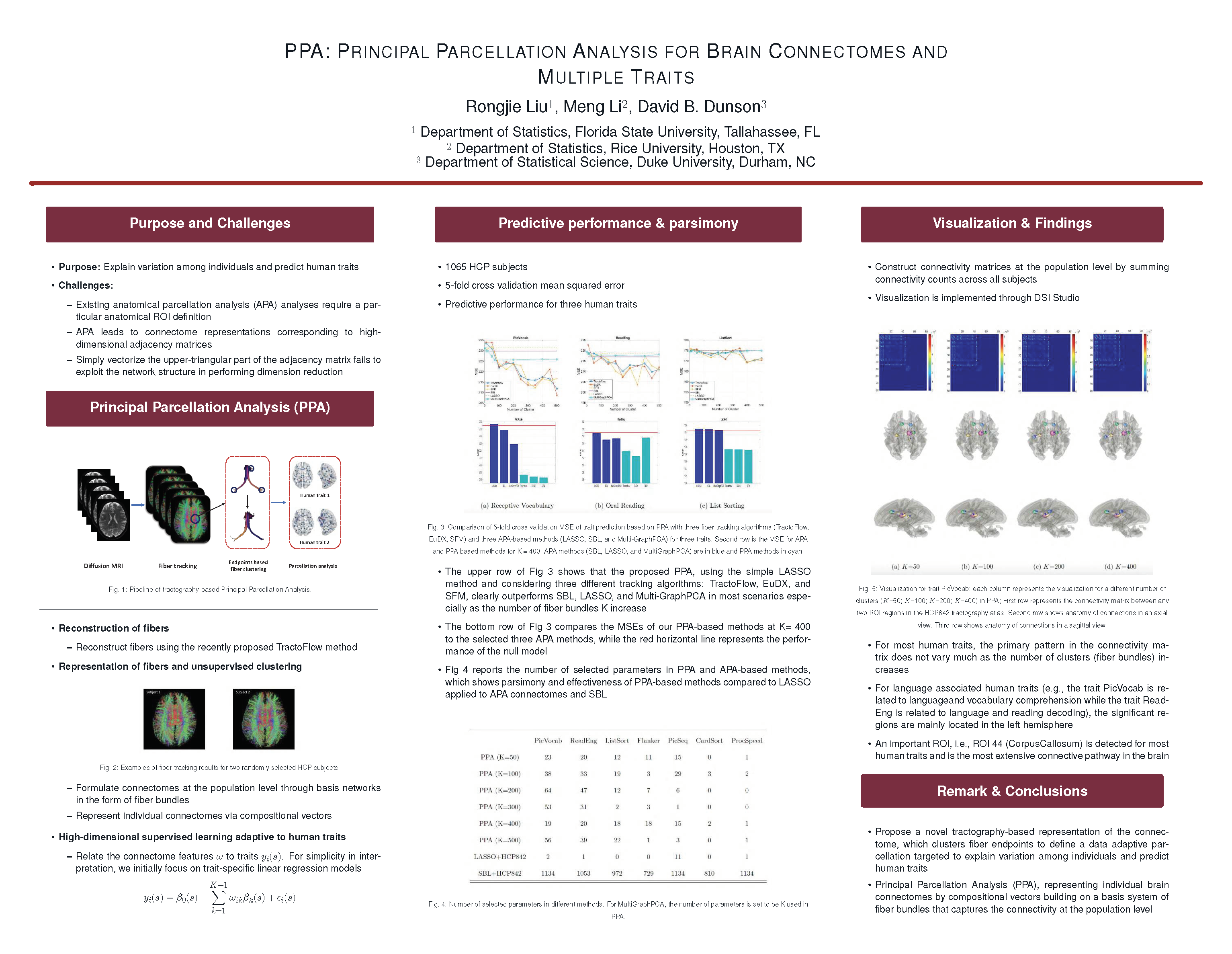
Abstract: Our understanding of the structure of the brain and its relationships with human traits is largely determined by how we represent the structural connectome. Standard practice divides the brain into regions of interest (ROIs) and represents the connectome as an adjacency matrix having cells measuring connectivity between pairs of ROIs. Statistical analyses are then heavily driven by the (largely arbitrary) choice of ROIs. We propose a novel tractography-based representation of brain connectomes, which clusters fiber endpoints to define a data adaptive parcellation targeted to explain variation among individuals and predict human traits. This representation leads to Principal Parcellation Analysis (PPA), representing individual brain connectomes by compositional vectors building on a basis system of fiber bundles that captures the connectivity at the population level. PPA reduces subjectivity and facilitates statistical analyses. We illustrate the proposed approach through applications to data from the Human Connectome Project (HCP) and show that PPA connectomes improve power in predicting human traits over state-of-the-art methods based on classical connectomes while dramatically improving parsimony and maintaining interpretability.
Poster 4. Elastic Shape Analysis of Brain Structures for Predictive Modeling of PTSD
Yuexuan Wu
Florida State University
Email: yw17g@my.fsu.edu
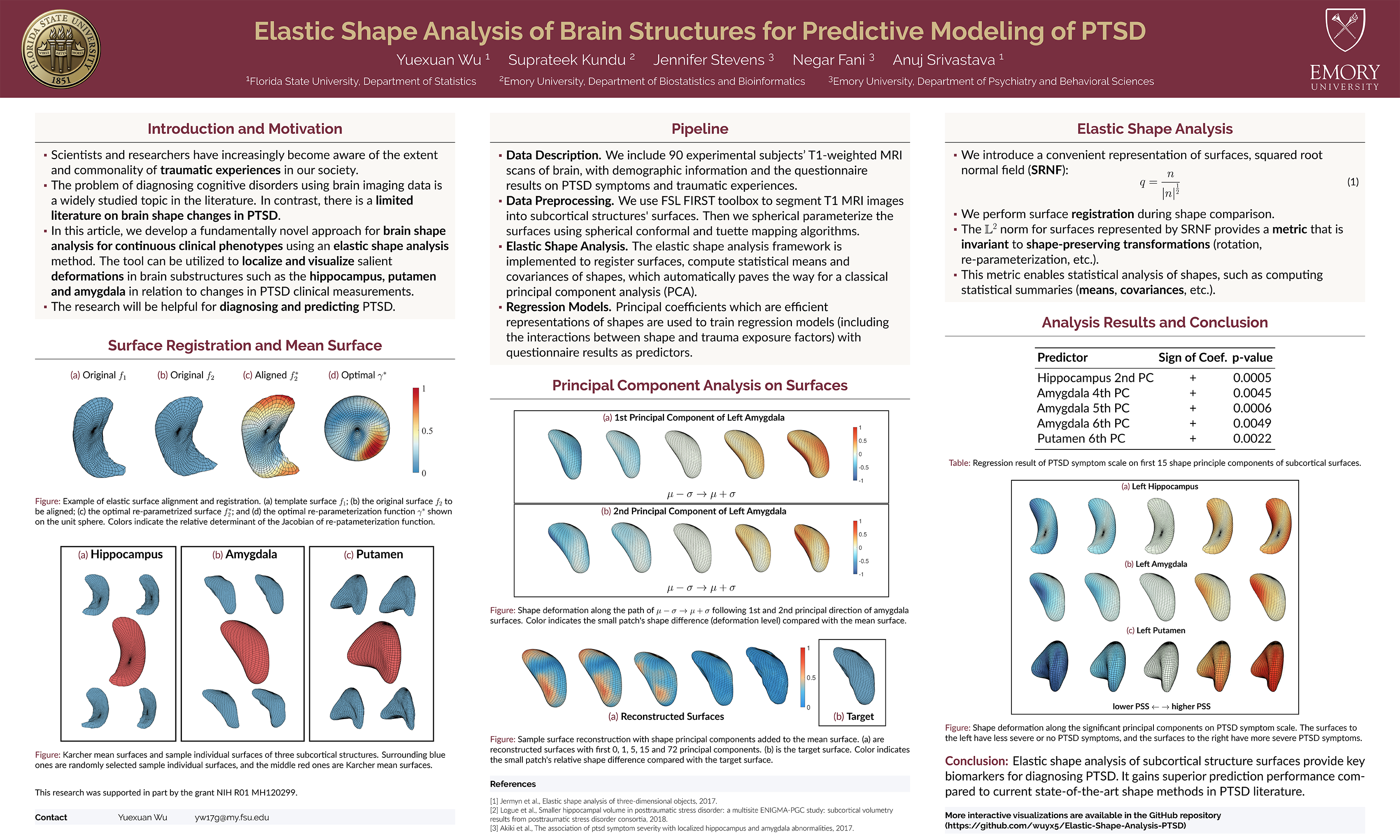
Abstract: There is increasing evidence on the importance of brain morphology in predicting and classifying mental disorders and behavior. However, most current shape approaches rely heavily on vertex-wise analysis that may not successfully capture complexities of subcortical structures. Additionally, the past works do not include interactions between these structures and exposure factors when modeling clinical or behavioral outcomes. Predictive modeling with such interactions is of paramount interest in heterogeneous mental disorders such as PTSD, where trauma exposure and other factors interact with brain shape changes to influence behavior. We propose a comprehensive framework that overcomes these limitations by representing brain substructures as continuous parameterized surfaces and quantifying their shape differences using elastic shape metrics. Using the elastic shape metric, we compute shape summaries (mean, covariance, PCs) of subcortical data and represent individual shapes by their principal scores under a PCA basis. These representations allow visualization tools that help understand localized changes when these PCs are varied. Subsequently, these PCs, the auxiliary exposure variables, and their interactions are used for regression modeling and prediction. We apply our method to data from the Grady Trauma Project (GTP), where the goal is to predict clinical measures of PTSD using shapes of brain substructures such as the hippocampus, amygdala, and putamen. Our analysis revealed considerably greater predictive power under the elastic shape analysis than widely used approaches such as the standard vertex-wise shape analysis and even a volumetric analysis. It helped identify local deformations in brain shapes related to change in PTSD severity. To our knowledge, this is one of the first brain shape analysis approaches that can seamlessly integrate the pre-processing steps under one umbrella for improved accuracy and are naturally able to account for interactions between brain shape and additional covariates to yield superior predictive performance when modeling clinical outcomes. Interactive visualizations are available in the GitHub repository (https://github.com/wuyx5/Elastic-Shape-Analysis-PTSD).
Poster 5. Multi-scale Graph Principal Component Analysis for Connectomics
Steven Winter
Duke University
Email: steven.winter@duke.edu
Abstract: In brain connectomics, it is common to divide the cortical surface into discrete regions of interest (ROIs) and then to use these regions to induce a graph. The structure of the resulting adjacency matrices depends critically on the chosen regions, leading to dramatically different inference when different regions are chosen. To solve this problem we develop a multi-scale graph model, which links together scale-specific factorizations through common individual-specific latent factors. These scores combine information across from different parcellations to produce a single interpretable summary of an individuals brain structure. We develop a simple, efficient algorithm, and illustrate substantial advantages over comparable single-scale methods in both simulations and analyses of the Human Connectome Project dataset.
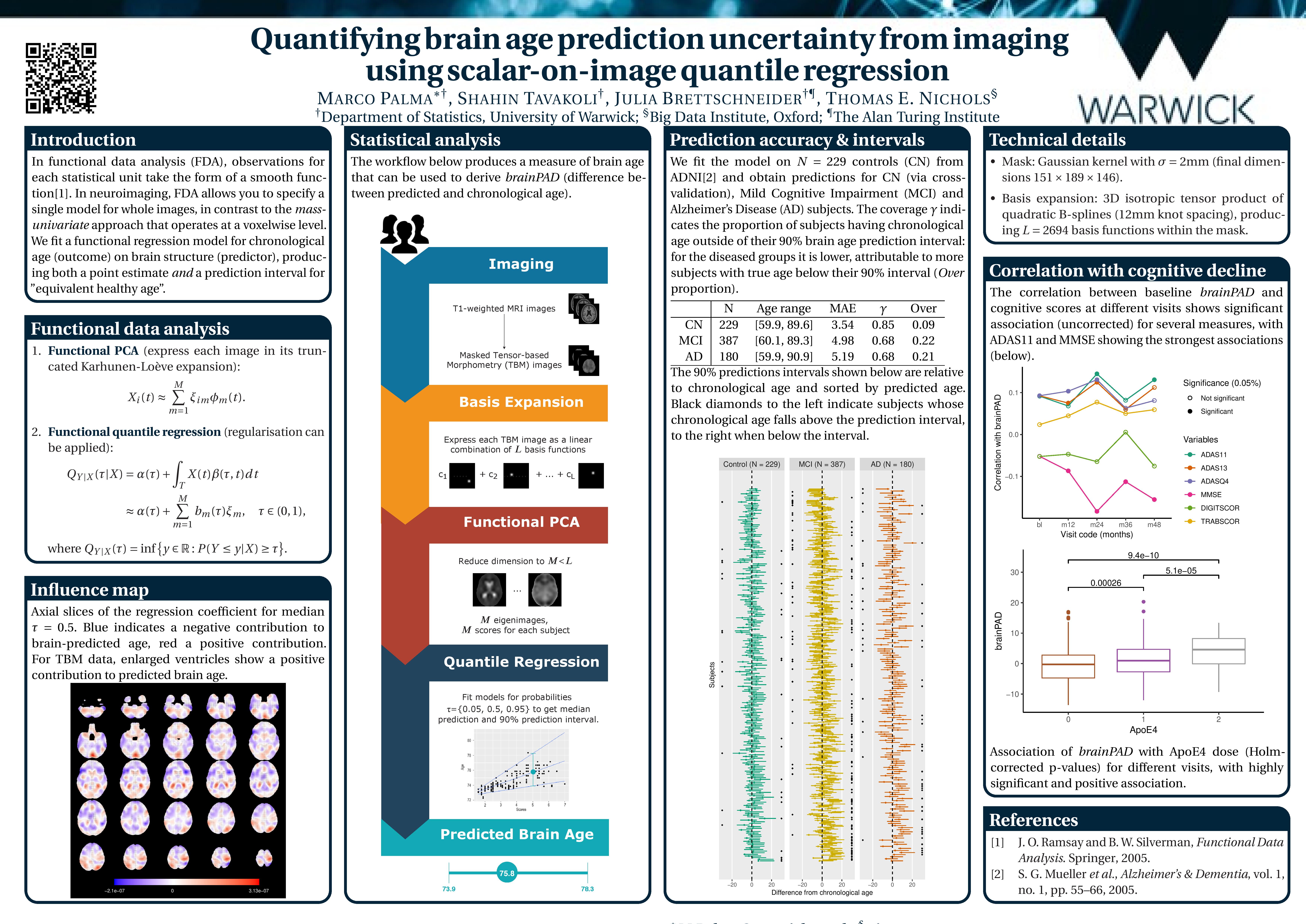
Poster 6. Quantifying brain age prediction uncertainty from imaging using scalar-on-image quantile regression
Marco Palma
University of Warwick
Email: M.Palma@warwick.ac.uk
Abstract: Prediction of subject age from brain anatomical MRI has the potential to provide a sensitive summary of brain changes, indicative of different neurodegenerative diseases. However, existing studies typically neglect the uncertainty of these predictions. In this work we take into account this uncertainty by applying methods of functional data analysis. We propose a penalized functional quantile regression model of age on brain structure with cognitively normal (CN) subjects in the Alzheimer’s Disease Neuroimaging Initiative (ADNI) and use it to predict brain age in Mild Cognitive Impairment (MCI) and Alzheimer’s Disease (AD) subjects. Unlike the machine learning approaches available in the literature of brain age prediction, which provide only point predictions, the outcome of our model is a prediction interval for each subject. The prediction accuracy obtained with this model is similar to more sophisticated approaches, while being also more principled and interpretable. The gap between predicted and chronological age correlates with cognitive decline.
Poster 7. Outlier Detection for Multi-Network Data
Pritam Dey
Duke University
Email: pritam.dey@duke.edu
Abstract: It has become routine in neuroscience studies to measure brain networks for different individuals using neuroimaging. These networks are expressed as adjacency matrices, with each cell containing a summary of connectivity between a pair of brain regions. There is an emerging statistical literature describing methods for the analysis of such multi-network data in which nodes are common across networks, but the edges vary. However, such brain connectome data often consist of outliers from various sources. First, the data can be corrupted by noise from various sources during the data collection phase like physical movement of the subject during the scanning process. In addition, structural connectivity reconstruction is a complex process, consisting of many steps and relying on many different open-source software suites. A small mistake in the pipeline (e.g., brain tissue segmentation error) will be propagated and amplified to the final connectivity output. . For such individuals, the resulting adjacency matrix may be mostly zeros or may exhibit a bizarre pattern not consistent with a normal brain network. Previous quality controls of these pipelines heavily rely on man power through visualization of intermediate results, which is time consuming and impractical for large datasets such as UK Biobank. However, if not accounted for carefully, the outlying connectomes can be influential in subsequent statistical analyses. We propose a simple method for network outlier detection (NOD) relying on an approximation of the influence function under a hierarchical generalized linear model for the adjacency matrices. Our NOD method is illustrated through an application to data from the UK Biobank.
Poster 8. Structural Brain Asymmetries in Youths with Combined and Inattentive Presentations of Attention Deficit Hyperactivity Disorder
Cintya Nirvana Dutta
King Abdullah University of Science and Technology
Email: cintya.dutta@kaust.edu.sa
Abstract: Alterations in structural brain asymmetry are reported in attention- deficit/hyperactivity disorder (ADHD). Here we replicate left-right asymmetry in combined and inattentive ADHD. Methods: We investigate asymmetry index (AI) across 13 subcortical and 33 cortical regions from anatomical metrics of volume, surface area, and thickness. Structural T1- weighted MRI data were obtained from youths with ADHD-C (n1 = 51) and ADHD-I (n2 = 64), and aged-matched controls (n0 = 298). We used a linear mixed effects model that accounts for data site heterogeneity, while studying associations between AI and covariates of presentation and age. Results: After study-wide correction for multiple comparisons, ADHD-Inattentive had greater rightward asymmetry in thickness of the inferior temporal (t = −3.72, p-value < 10−5), along with age (t = 3.54, p-value < 10−5). Regions that did not satisfy the multiple testing correction support functional MRI results of disrupted connectivity in motor networks from ADHD-C and default mode from ADHD-I. Conclusions: Temporal deficits may differentiate ADHD presentations. Symptom severity can determine if brain asymmetry patterns are causal or compensatory. Significance: Structural brain asymmetry may provide neurobiological insight into ADHD presentations. Using linear mixed effects model, one can conduct formal statistical inference on associations between brain asymmetries, diagnosis, and neurodevelopment.
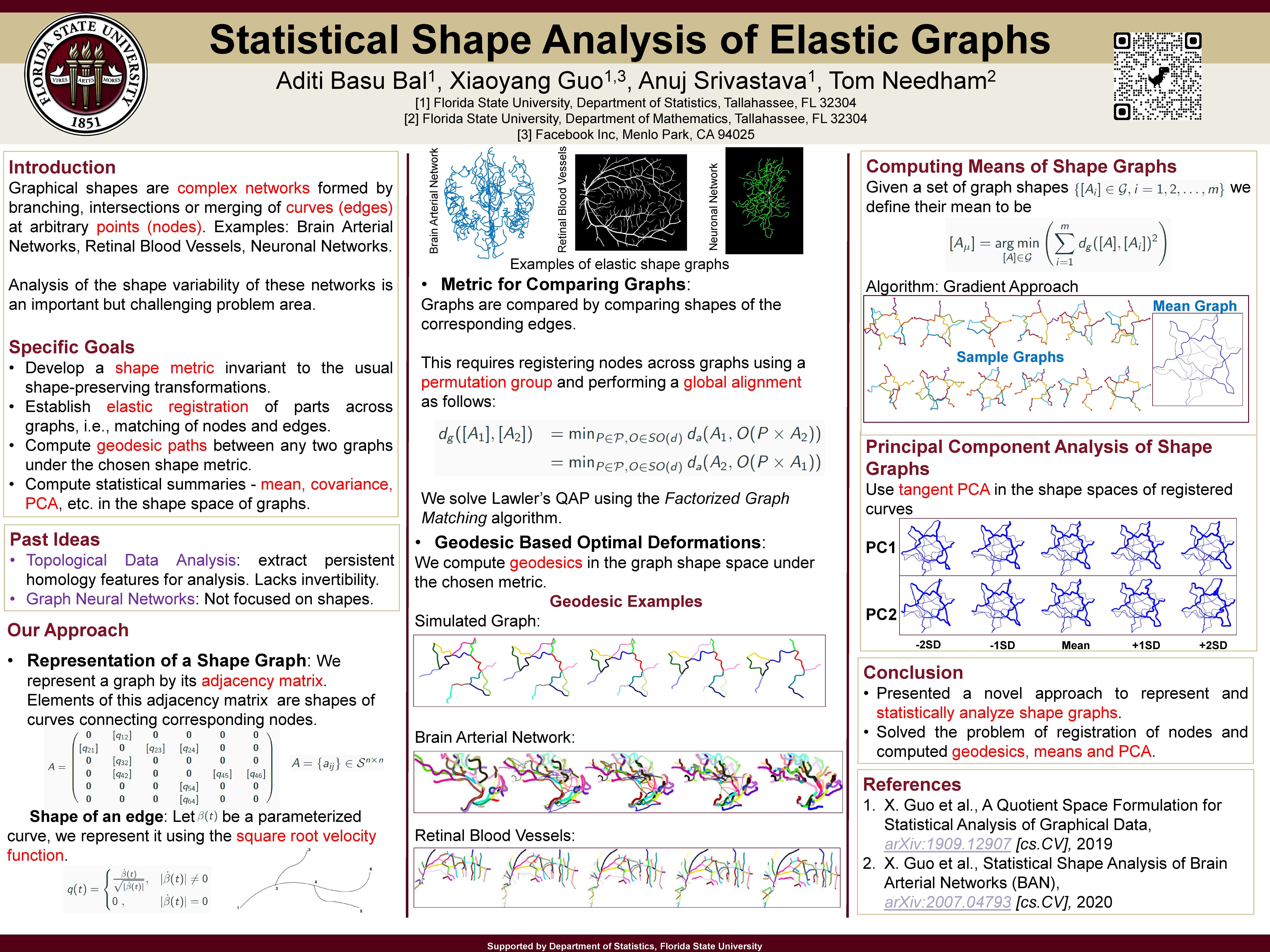
Poster 9. Statistical Shape Analysis of Elastic Graphs
Aditi Basu Bal
Florida State University
Email: juhu.basu@gmail.com
Abstract: This research project develops a comprehensive framework for generative statistical analysis of elastic shape graphs. Examples of such graphs include road networks, brain arterial networks, brain fiber tracts, retinal blood vessels, etc. We represent an elastic shape graph as a collection of nodes that are connected by (2D or 3D) curves or edges with arbitrary shapes. Using a novel mathematical representation and a Riemannian metric on this representation, we seek geometrical tools such as computations of geodesics, means and covariances, and PCA, for modeling and testing such graphical shapes. This work further introduces an efficient method to calculate means of shape graphs and also explores the use of landmarks in improving registration of nodes. These ideas are illustrated using simulated as well as real data examples.
Poster 10. BICNet: A Bayesian Approach for Estimating Task Effects on Intrinsic Connectivity Networks in fMRI Data
Meini Tang
King Abdullah University of Science and Technology
Email: meini.tang@gmail.com
Abstract: Intrinsic connectivity networks (ICNs) are specific dynamic functional brain networks that are consistently found under various conditions including rest and task. Studies have shown that some stimuli actually activate intrinsic connectivity through either suppression, excitation, moderation or modification. Nevertheless, the structure of ICNs and task-related effects on ICNs are not yet fully understood. In this paper, we propose a Bayesian Intrinsic Connectivity Network (BICNet) model to identify the ICNs and quantify the task-related effects on the ICN dynamics. Using an extended Bayesian dynamic sparse latent factor model, the proposed BICNet has the following advantages: (1) it simultaneously identifies the individual ICNs and group-level ICN spatial maps; (2) it robustly identifies ICNs by jointly modeling resting-state functional magnetic resonance imaging (rfMRI) and task-related functional magnetic resonance imaging (tfMRI); (3) compared to independent component analysis (ICA)-based methods, it can quantify the difference of ICNs amplitudes across different states; (4) it automatically performs feature selection through the sparsity of the ICNs rather than ad-hoc thresholding. The proposed BICNet was applied to the rfMRI and language tfMRI data from the Human Connectome Project (HCP) and the analysis identified several ICNs related to distinct language processing functions.
Poster 11. Evaluation of color space transformations in separating anemia vs control subjects
Chenlu Shan
Emory University
Email: chenlu.shan@emory.edu
Abstract: Anemia detection requires invasive blood testing with the gold standard hemoglobin level by a complete blood count (CBC). This procedure involves phlebotomy, which could lead to certain adverse effects. We consider a recently proposed non-invasive method for monitoring anemia with a fingernail image taken from patients. Non-invasive anemia detection involves procedure of extracting color data from patients’ fingernail bed smartphone images. The color data are extracted in RGB (Red, Green, Blue) color space. Since it is unknown that which color space transformation is most useful in discriminating anemia population vs healthy population, our work focused on determining which transformation of RGB (Red, Green, Blue) data would produce the best separation among anemic and control subjects. Several metrics are used to access the separation between anemia and healthy groups based on within sum of squares and between sum of squares (Metric 1: Ratio of within variation to between variation). It is shown that HSI (Hue, Saturation, Intensity) color space performs the best in comparison to all other color spaces (Metric 1: 1.02, (95% CI: 0.82-1.35) for HSI, Metric 1: 0.76 (95% CI: 0.56-1.05) for RGB). The HSI color space also produced the lowest mean squared errors in predicting anemia status using Lasso Regression method (MSE for HSI: 0.085, For RGB: 0.096). We conclude HSI color space as the best color space in separating anemia vs control.
Poster 12. Analysis of multichannel brain signals via nonparametric Bayesian mixtures of autoregressive kernels
Guillermo Cuauhtemoctzin Granados Garcia
King Abdullah University of Science and Technology
Email: guillermo.granadosgarcia@kaust.edu.sa
Abstract: To analyze multichannel brain signals, we develop a novel approach to identify the most prevalent oscillatory activity within each channel and decompose the multivariate signals in their common oscillatory patterns present among channels to characterize different types of associations between pairs of channels. The current approach is to analyze power at subjectively predefined frequency bands; this is a serious limitation because it does not allow the data to identify specific peaks power and location that are associated with the cognitive demands. To overcome the limitations of current approaches, we develop the Multivariate Bayesian Mixture Auto-Regressive Decomposition (MBMARD) that identifies from the data (rather than apriori assumed) (i) the number of common prominent peaks across channels, (ii) the frequency peak locations, and (iii) their corresponding spread of power around the peaks. The MBMARD method jointly model the spectral functions of multichannel signals as a multimodal PDF via a Dirichlet Process (DP) mixture based on a kernel derived from second-order auto-regressive processes (AR(2)) with unique spectral density having a single peak. Under the MBMARD approach, the multichannel signals are modeled as a mixture of AR(2) latent processes capturing the associations strength between channels through the mixture weights from the DP model. The simulation studies demonstrate the robustness and performance of the MBMARD method. We present the analysis of local field potential (LFP) activity on multiple tetrodes from the hippocampus of laboratory rats during a non spatial memory task giving new insightful results on frequency specific power changes over different experimental conditions. We also present a second analysis on multichannel human EEG data from an alcoholic and control subjects were MBMARD accounts for between-subject variation in capturing frequency-specific power associations among different brain regions.
Poster 13. A Regression Framework for Brain Network Distance Metrics
Chalmer Tomlinson
UNC Chapel Hill
Email: chalmer.tomlinson@gmail.com
Abstract: Analyzing brain networks has long been a prominent research topic in neuroimaging. However, statistical methods to detect differences between these networks and relate them to phenotypic traits are still sorely needed. Our previous work developed a novel permutation testing framework to detect differences between two groups. Here we advance that work to allow both assessing differences by continuous phenotypes and controlling for confounding variables. To achieve this, we propose an innovative regression framework to relate distances between brain network features to functions of absolute differences in continuous covariates and indicators of difference for categorical variables. We explore several similarity metrics for comparing distances between connection matrices, and adapt several standard methods for estimation and inference within our framework: Standard F-test, F-test with individual level effects (ILE), Generalized Least Squares (GLS), Mixed Model, and Permutation. We also propose a novel modification of the standard GLS approach for estimation and inference. We assess all approaches for estimation and inference via simulation studies, and illustrate the utility of our framework by analyzing the relationship between fluid intelligence and brain network distances in Human Connectome Project (HCP) data.
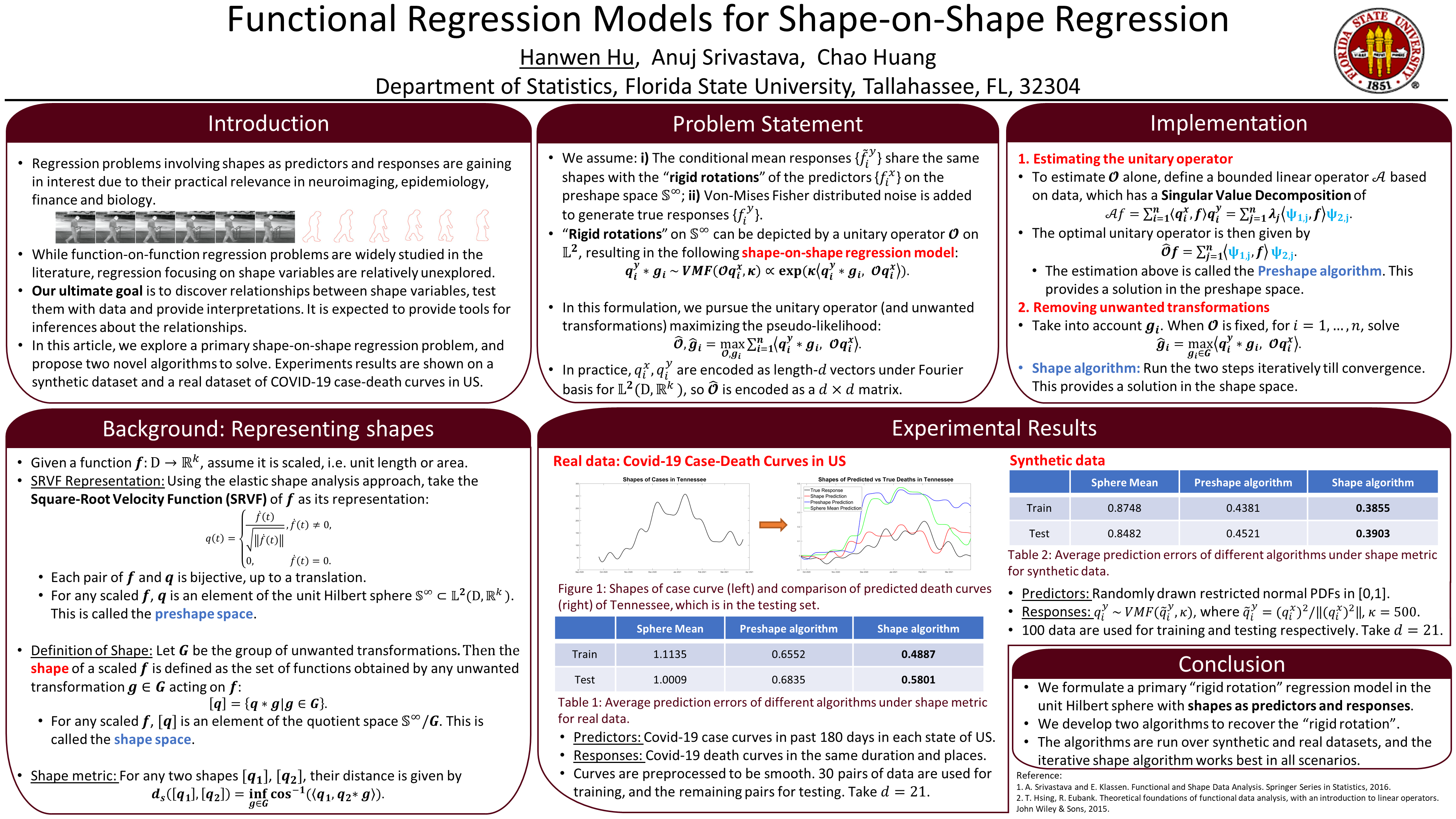
Poster 14. Shape-on-Shape Regression based on Unitary Operators
Hanwen Hu
Florida State University
Email: hh19j@my.fsu.edu
Abstract: We focus on a specific subproblem in functional regression models where both predictors and responses are "shapes" of functional variables. We can find examples of this problem in neuroimaging, epidemiology, finance, and biology. Taking the elastic shape analysis approach, we represent shapes of functions using the square-root velocity functions (SRVFs), elements of a unit Hilbert sphere or a preshape space. Removing the unwanted transformations (time warping, etc.) leads to a quotient space or a shape space. We model the conditional mean of the response shapes as "rigid rotations" of the predictors on the Hilbert sphere and the noise using the Fisher von Mises distribution. We derive the theory and algorithms for the pseudo-maximum-likelihood estimator of this unitary operator given observed paired data. This solution is developed in two steps: we first develop the estimation framework for the preshape space and then extend it to the shape space. We demonstrate these ideas on two synthetic datasets as well as a real dataset, the pairs of Covid-19 case curves and death curves in 51 US states.
Poster 15. Image-on-scalar Regression with Latent Subgroup Identification using Expectation Maximization
Zikai Lin
University of Michigan
Email: zikai@umich.edu
Abstract: Image-on-scalar regression has been a popular approach to modeling the association between brain activities (image response) and clinical characteristics (scalar predictors) in neuroimaging research. The recent large neuroimaging studies, e.g., the Adolescent Brain Cognitive Development (ABCD) study, indicate that this type of association may be heterogenous across individuals in the population. It is of great interest to identify subgroups of individuals from the population such that: 1) within each subgroup the brain activity is homogenously associated with the clinical characteristics; 2) across subgroups the associations are different; and 3) the group allocation depends on individual characteristics. The existing image-on-scalar regression methods, such as the spatially varying coefficient model (SVCM) and other clustering methods, e.g., k-means, cannot directly achieve this goal. To address this challenge, we propose a novel latent subgroup image-on-scalar regression model (LASIR) for analysis of large-scale and heterogenous neuroimaging data collected from multiple sites. In LASIR, we introduce the latent subgroup indicator for each individual, the group-specific spatially varying coefficients and random effects for experimental sites. We adopt an efficient stochastic expectation maximization algorithm for model inferences. We demonstrate that LASIR outperforms the existing alternatives for subgroup identification of brain activation patterns via extensive simulations and analyses of working-memory task fMRI data in the ABCD study.
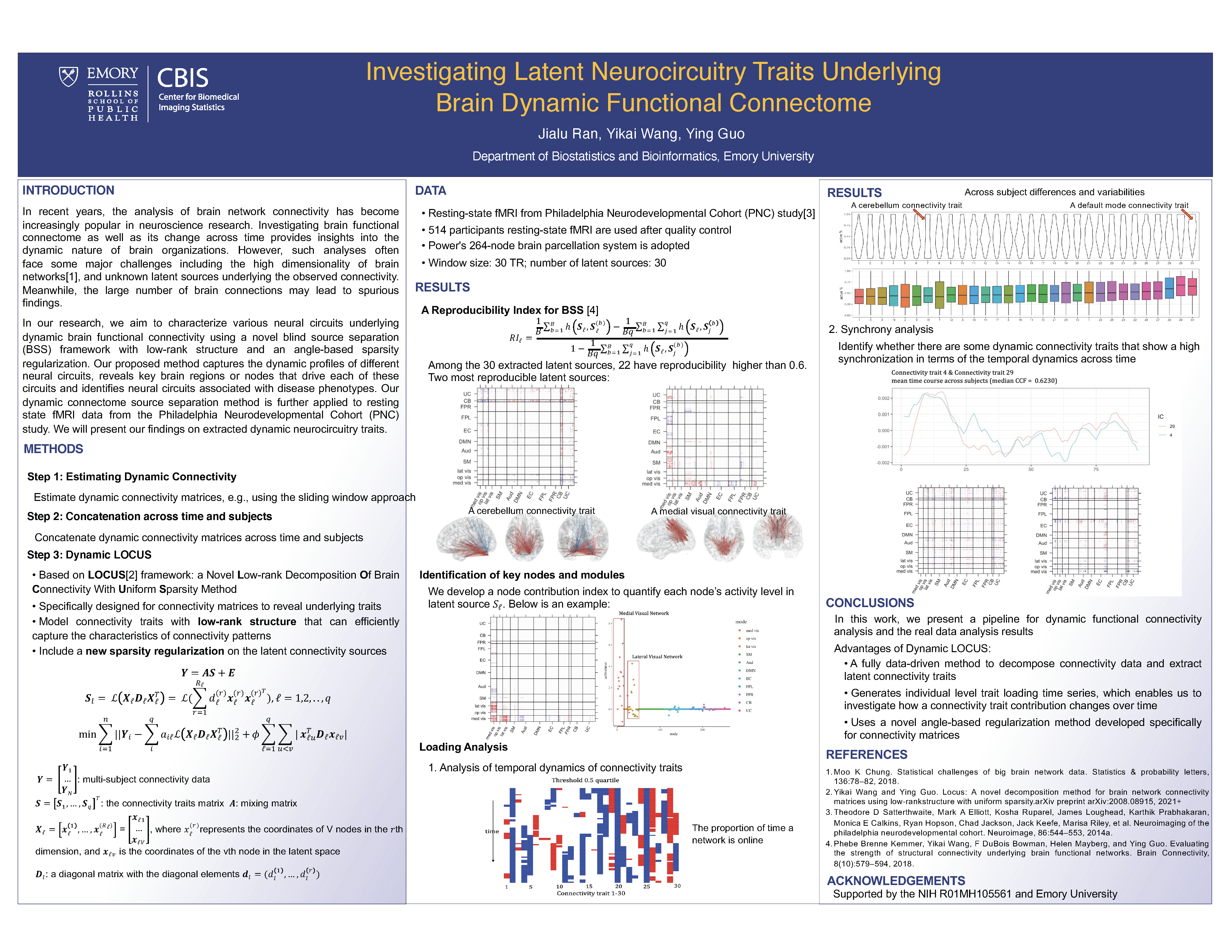
Abstract: In recent years, the analysis of brain network connectivity has become increasingly popular in neuroscience research. Investigating brain functional connectome as well as its change across time provides insights into the dynamic nature of brain organizations. However, such analyses often face some major challenges including the high dimensionality of brain networks, and unknown latent sources underlying the observed connectivity. Meanwhile, the large number of brain connections may lead to spurious findings. In our research, we aim to characterize various neural circuits underlying dynamic brain functional connectivity using a novel blind source separation (BSS) framework with a low-rank structure and an angle-based sparsity regularization. Our proposed method captures the dynamic profiles of different neural circuits, reveals key brain regions or nodes that drive each of these circuits and identifies neural circuits associated with disease phenotypes. Our dynamic connectome source separation method is further applied to resting-state fMRI data from the Philadelphia Neurodevelopmental Cohort (PNC) study. We will present our findings on extracted dynamic neurocircuitry traits.
Poster 17. BLMM: Parallelized Computing for Big Linear Mixed Models
Thomas Maullin-Sapey
University of Oxford
Email: thomas.maullin-sapey@linacre.ox.ac.uk
Abstract: Population neuroimaging datasets have transformed fMRI sample sizes from tens to thousands of subjects. As sample sizes grow, researchers face mounting pressure to detect and account for complex covariance structures induced by the grouping factors present in the experimental design. Methods conventionally employed for drawing inference on neuroimaging data (e.g. Ordinary Least Squares regression, t-tests and F-tests) often cannot account for the grouping structures present in large datasets and, consequently, can produce erroneous inferences. The linear mixed model (LMM) presents a flexible tool applicable to analyze longitudinal, heterogeneous or unbalanced clustered data. Here, we present BLMM ("Big" Linear Mixed Models); an efficient tool for large-scale LMM analyses, implemented in python and designed for use on SGE computer clusters.
Poster 18. Integrative Learning for Population of Dynamic Networks with Covariates
Jin Ming
Emory University
Email: jming2@emory.edu
Abstract: Although there is a rapidly growing literature on dynamic connectivity methods, the primary focus has been on separate network estimation for each individual, which fails to leverage common patterns of information. We propose novel graph-theoretic approaches for estimating a population of dynamic networks that are able to borrow information across multiple heterogeneous samples in an unsupervised manner and guided by covariate information. Specifically, we develop a Bayesian product mixture model that imposes independent mixture priors at each time scan and uses covariates to model the mixture weights, which results in time-varying clusters of samples designed to pool information. The computation is carried out using an efficient Expectation-Maximization algorithm. Extensive simulation studies illustrate sharp gains in recovering the true dynamic network over existing dynamic connectivity methods. An analysis of fMRI block task data with behavioral interventions reveal sub-groups of individuals having similar dynamic connectivity, and identifies intervention-related dynamic network changes that are concentrated in biologically interpretable brain regions. In contrast, existing dynamic connectivity approaches are able to detect minimal or no changes in connectivity over time, which seems biologically unrealistic and highlights the challenges resulting from the inability to systematically borrow information across samples.
Poster 19. Meta Regression for Coordinate Based Meta Analysis Data with a Spatial Model
Yifan Yu
University of Oxford
Email: yifan.yu@keble.ox.ac.uk
Abstract: The most widely used methods for Coordinate Based Meta-Analysis (CBMA) are all based on a mass-univariate approach that does not explicitly model the spatial smoothness of the distribution of activation foci. Some methods, like ALE, lack an interpretable parameter map which makes regression modelling or group comparisons challenging. We propose a spatial model that treats the foci as instances of an inhomogeneous Poisson process. We use a log-linear regression with either a Poisson model or a Negative Binomial model that can account for excess variance. This provides a generative regression model that estimates a smooth intensity function, and can have group-specific intensity functions and study-level regressors. While similar spatial Bayesian methods have been proposed, this frequentist model uses a 3D tensor product B-spline basis to efficiently model the entire image jointly. We demonstrate the method on a meta-analysis of working memory (WM), comparing studies using verbal stimuli vs studies using non-verbal stimuli.
Poster 20. Topological data analysis of dependence structure in brain networks
Anass El Yaagoubi Bourakna
KAUST
Email: anass.bourakna@kaust.edu.sa
Abstract: Detecting meaningful pattern structures in neural activity is a key task in neuroscience. Recent developments in the field of topological data analysis (TDA) produced tools for practitioners to study and explore the shape of brain data such as electroencephalogram/local field potentials; such methods are useful to derive powerful classification algorithms. Classical approaches for time series analysis provide tools to analyze “classical features” (such as cross-correlation, cross-cohrerence, partial coherence etc.) of the time series; those features are sensitive to many data transformations and thus are not always robust. In contrast, TDA offers a new set of features that provide a summary of the data that has a topological meaning, which is not always easily interpretable. However, such approaches that consist in the use of TDA to unravel the shape of data directly can be limited, especially when dealing with stationary snippets of brain signals. There are not many papers in TDA literature that explore brain dependence structure. In this poster, we propose a method that explores topological features of coherence matrices. The proposed TopDep method provides a meaningful topological summary of the observed brain signals. We call those topological summaries persistence surfaces (PSs). At every frequency, the PS displays a persistence landscape that summaries the topological shape of dependence using the homology groups of different dimensions. The center of the empirical distribution of the sample PSs is the analogue of the population’s PS, because of the random nature of such summary. To illustrate the ideas above we provide interesting simulations that display a topological behavior in the dependence structure of a population of persistence surfaces and how it can detect outliers. As a next step we will analyze EEG data to show topological behavior in the dependece structure of brain signals. The proposed summary is frequency specific (i.e., the topological features are allowed to change across frequency bands) and has the ability to capture the interesting patterns that are present in the data. We derive testing procedures based on the bootstrap and permutation approaches that are frequency band specific. This work demonstrates that the persistence surfaces are a powerful new tool for dependence matrix analysis in brain signals, where the brain connectivity network might display interesting topological behavior.
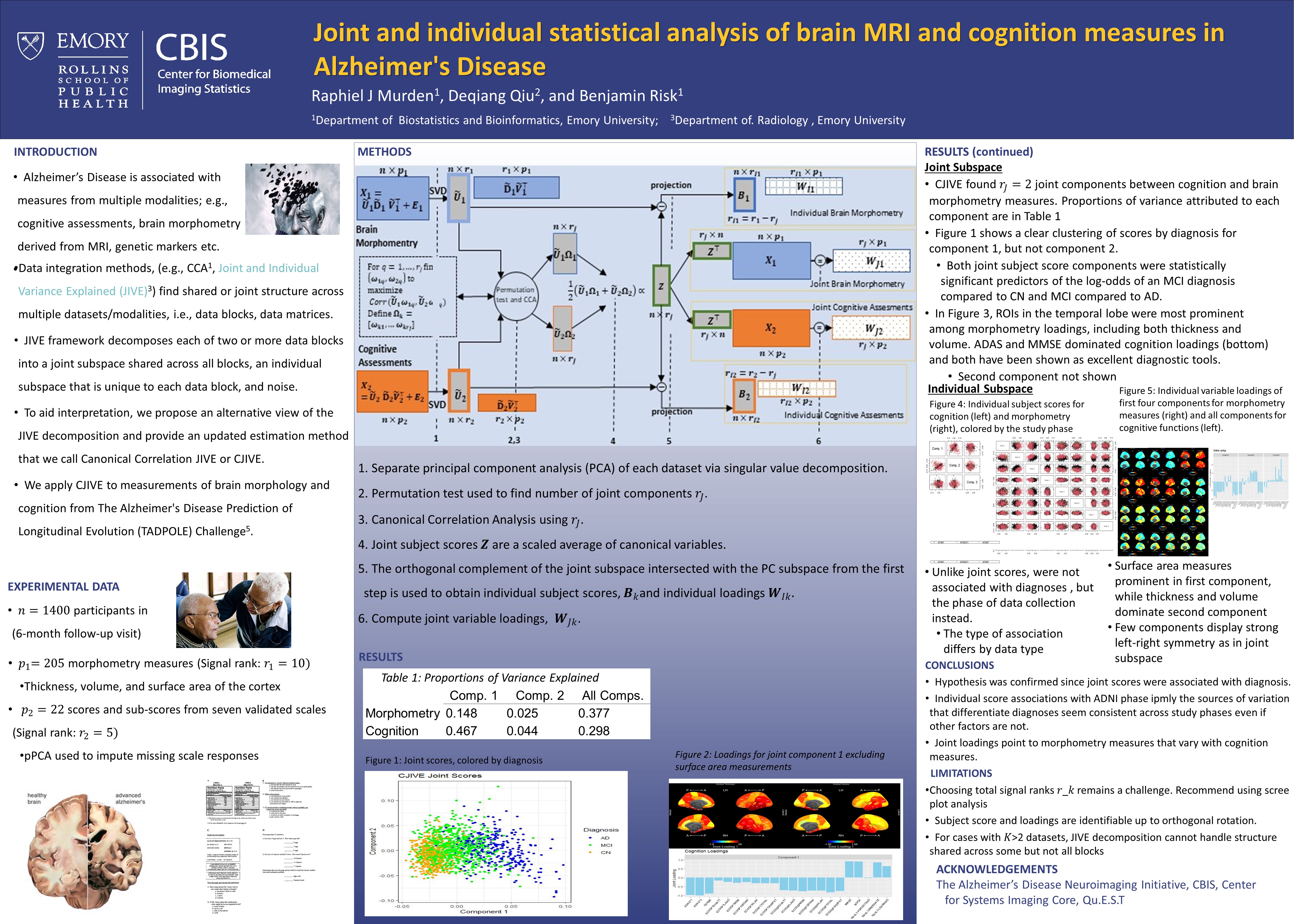
Poster 21. Joint and individual statistical analysis of brain MRI and cognition measures in Alzheimer's Disease
Raphiel Murden
Emory University
Email: r.j.murden@emory.edu
Abstract: Alzheimer's Disease is associated with changes that can be measured using multiple modalities such as cognitive assessment and brain volumetry using MRI. Data integration methods, such as the classic Hotelling's canonical correlation analysis (CCA) can find shared or joint structure across multiple datasets/modalities (i.e. data blocks, data matrices). More recent approaches include multiset Canonical Correlation Analysis or M-CCA, Joint and Individual Variance Explained (JIVE), Angle-based JIVE (AJIVE), and others. The JIVE framework decomposes each of two or more data blocks into a joint subspace shared across all blocks, an individual subspace that is unique to each data block, and noise. Here, individual refers to signal unique to a dataset. However, interpreting these subspaces remains challenging. To aid interpretation, we propose an alternative view of the JIVE decomposition and provide an updated estimation method called Canonical JIVE or CJIVE. We apply CJIVE to measurements of brain morphology and cognition from The Alzheimer's Disease Prediction of Longitudinal Evolution (TADPOLE) Challenge. Our results show the utility of JIVE analyses by obtaining summary measures of the signal shared in our morphometry and cognition measures are associated with Alzheimer’s diagnoses.
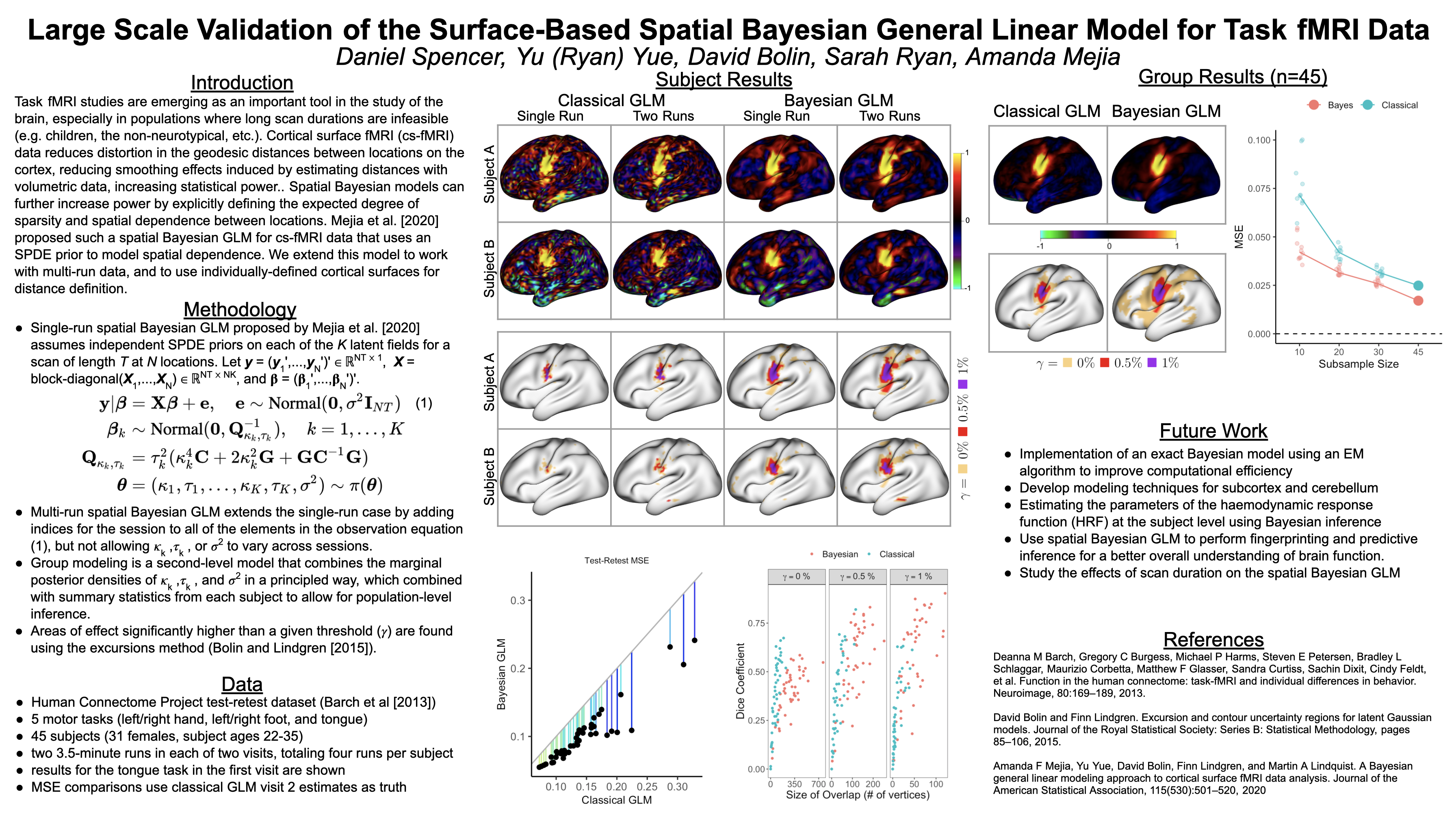
Poster 22. Large Scale Validation of the Spatial Bayesian General Linear Model for Cortical Surface fMRI Data
Daniel Spencer
Indiana University
Email: danieladamspencer@gmail.com
Abstract: Functional magnetic resonance imaging (fMRI) data over a noninvasive measure for interpreting neuronal processes in subjects in vivo at relatively high spatial and temporal resolutions. Task fMRI is an imaging technique in which a subject is exposed to a stimulus, sometimes with an expected response, in order to assess how the brain reacts. However, the signal-to-noise ratio in preprocessed task fMRI data remains low, requiring innovative methods in order to provide the most statistical power possible. Bayesian spatial methods allow for explicit, probabilistic definitions of the expected underlying signal spatial dependence, offering significant increases to model power through efficient use of available data. However, most such methods analyze fMRI data that incorporate spatial dependencies via the locations in the brain represented as a volume. Such models use distance-based dependence modeling using Euclidean distance, which can drastically distort the geodesic distances along the folded cortex, resulting in oversmoothed activation amplitude estimates and reduced power. An alternative is to examine data on the cortical surface, which allows for more accurate measures of distance between data locations. A recent study proposed such a surface-based spatial Bayesian general linear model (GLM) for task fMRI and showed improvements when estimating activation amplitude and determining areas of significant brain activation. This promising study necessitates large scale validation in order to convincingly demonstrate the value of the method to the broader neuroscience community. In this study, we validate the surface-based spatial Bayesian GLM using a dataset of test-retest motor task data from the HCP. We assess the reliability and power of individual and group-average task activations. In addition, we extend the surface-based spatial Bayesian GLM to incorporate multiple runs in single-subject analyses. Comparisons to a classical massive "univariate" GLM for cortical surface fMRI are included to show both improved power and reliability of the spatial Bayesian GLM.
Poster 23. Clustering brain extreme communities from multi-channel EEG data
Matheus Bartolo Guerrero
Indiana University
Email: matheus.bartologuerrero@kaust.edu.sa
Abstract: Epilepsy is a chronic neurological disorder affecting more than 50 million people globally. An epileptic seizure acts like a temporary shock to the neuronal system, disrupting normal electrical activity in the brain. Epilepsy is frequently diagnosed with electroencephalograms (EEGs). Current cluster methods for characterizing brain connectivity rely on the bulk of EEG distribution, such as coherence. Here, we use a spherical k-means procedure based on extreme amplitudes of EEG signals during an epileptic seizure. With this approach, cluster centers can be interpreted as extremal prototypes, revealing the dependence structures of EEG channel communities. The way cluster components relate to each other can be used as an exploratory tool to classify EEG channels into asymptotic independents or asymptotic dependents. We illustrate the use of this approach by an application to a real dataset from a patient with left temporal lobe epilepsy.
Poster 24. SpLoc: Permutation-based spatial scanning for detecting fMRI group-level activation clusters
Jun Young Park
University of Toronto
Email: junjy.park@utoronto.ca
Abstract: A new cluster-wise inference method, called SpLoc (“Spatially LOCalized signals”), is introduced to detect statistically significant voxels/vertices in neuroimaging data. SpLoc increases (i) sensitivity by taking the average of test statistics within each cluster defined by spatial neighbors and (ii) specificity by pruning off clusters consisting mainly of the non-signal voxels based on the orderings of the test statistics. It uses resampling approaches (sign-flipping/permutation) to estimate potentially nonstationary spatial correlations and control family-wise error. We apply it to the taskfMRI data from the Human Connectome Project and conduct simulation studies to address the SpLoc’s performance compared to the existing methods.
Poster 25. Higher Criticism to Understand the Complex Neural Underpinnings of Worry
Andrew Gerlach
University of Pittsburgh
Email: arg151@pitt.edu
Abstract: Background: Worry is a transdiagnostic phenotype encountered in multiple mental disorders and independently associated with increased morbidity, including cognitive impairment and cardiovascular diseases. We investigated the neurobiological basis of worry in older adults by analyzing resting fMRI from a systems neuroscience perspective. Methods: We collected resting fMRI on 77 participants (>50 yo) with varying worry severity. We computed region-wise connectivity across the Default Mode Network (DMN), Anterior Salience Network (ASN), and left Executive Control Network (LECN). All 22,366 correlations were regressed on worry severity and adjusted for age, sex, race, education, disease burden, depression, anxiety, rumination, and neuroticism. We employed higher criticism (HC) thresholding, a second-level method of significance testing for rare/weak features, for correlation selection. Aggregate correlations were used to summarize network-level signatures of worry. Results: Half the relevant intra-network connections are within DMN. Negative correlations with worry severity dominate throughout the cingulate, temporal lobe, and cuneus, while frontal regions show bidirectional associations with worry. Within ASN, negative correlations with worry severity abound, particularly in the ACC, inferior frontal regions, and thalamus. Positive correlations with worry severity in the left PCC and right temporal lobe and negative correlations in frontal regions are notable within LECN. Inter-network analysis reveals a rich, but complex pattern of connectivity. Conclusions: Worry severity is associated with complex resting state intra- and inter-network connectivity signatures independent of other clinical and demographic variables. Identifying the most salient and unique connections may be useful for targeted interventions for reducing morbidity associated with severe worry in older adults.
Poster 26. The Spike-and-Slab Elastic Net as a Classification Tool in Alzheimer's Disease
Justin Leach
University of Alabama at Birmingham
Email: jleach@uab.edu
Abstract: Alzheimer's disease (AD) is the leading cause of dementia and has received considerable research attention, including using neuroimaging biomarkers to classify patients and/or predict disease progression. Generalized linear models, e.g., logistic regression, can be used as classifiers, but since the spatial measurements are correlated and often outnumber subjects, penalized and/or Bayesian models will be identifiable, while classical models often will not. Many useful models, e.g., the elastic net and spike-and-slab lasso, perform automatic variable selection, which removes extraneous predictors and reduces model variance, but neither model exploits spatial information in selecting variables. Spatial information can be incorporated into variable selection by placing intrinsic autoregressive priors on the logit probabilities of inclusion within a spike-and-slab elastic net framework. We use cortical thickness and tau-PET images from the Alzheimer's Disease Neuroimaging Initiative (ADNI) study for binary classification of subjects who are cognitively normal, mildly cognitively impaired, or diagnosed with dementia to demonstrate that this framework can improve classification performance.
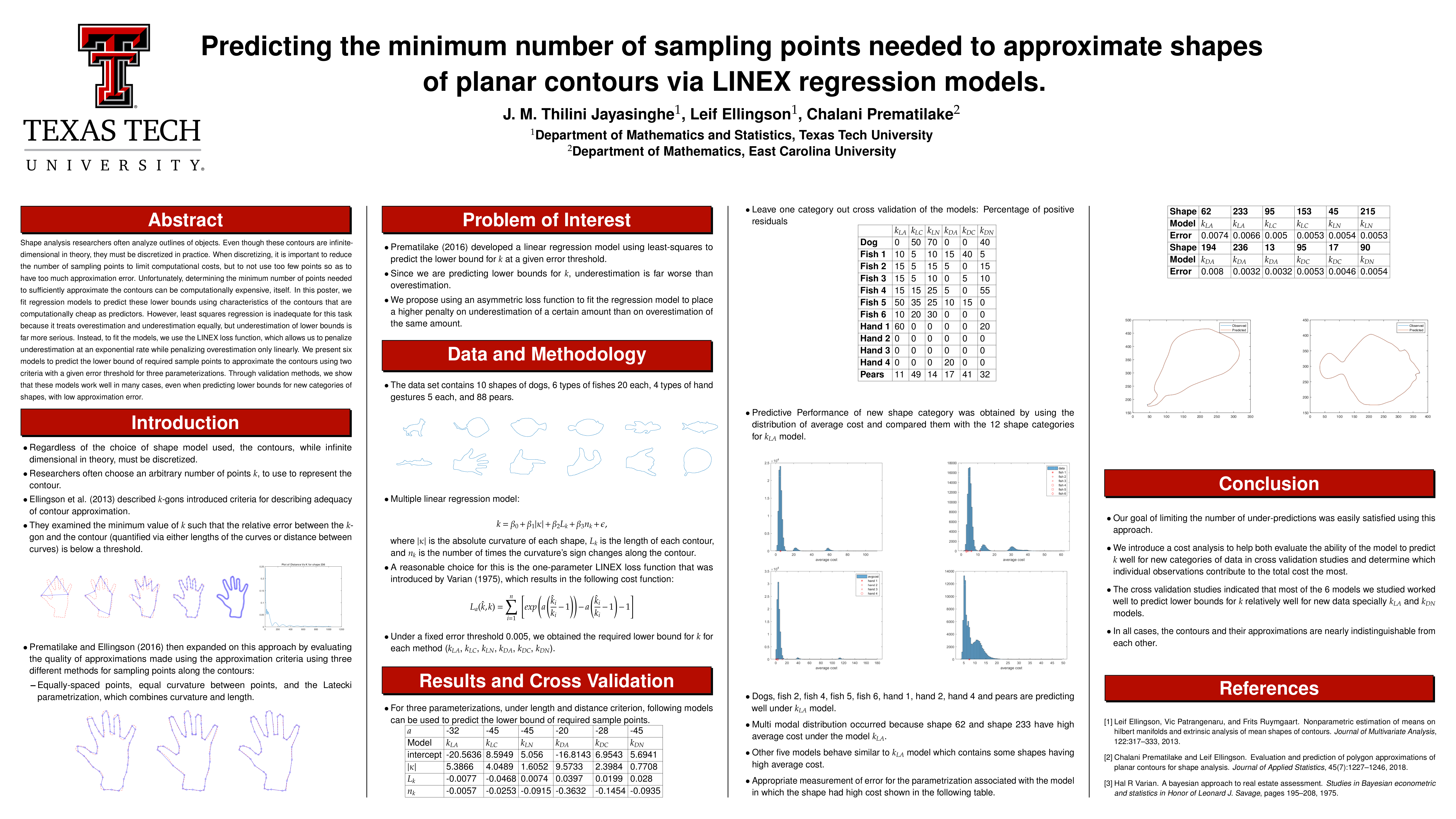
Poster 27. Predicting the minimum number of sampling points needed to approximate shapes of planar contours via LINEX regression models
J. M. Thilini Jayasinghe
Texas Tech University
Email: jmthilini-navoda.jayasinghe@ttu.edu
Abstract: Researchers in statistical shape analysis often analyze outlines of objects. Even though these contours are infinite-dimensional in theory, they must be discretized in practice. When discretizing, it is important to reduce the number of sampling points considerably to reduce computational costs, but to not use too few points so as to result in too much approximation error. Unfortunately, determining the minimum number of points needed to sufficiently approximate the contours can be computationally expensive, itself. In this paper, we fit regression models to predict these lower bounds using characteristics of the contours that are computationally cheap as predictor variables. However, least squares regression is inadequate for this task because it treats overestimation and underestimation equally, but underestimation of lower bounds is far more serious. Instead, to fit the models, we use the LINEX loss function, which allows us to penalize underestimation at an exponential rate while penalizing overestimation only linearly. We present six models to predict the lower bound of required sample points to approximate the contours using two criteria with a given error threshold for three parameterizations. Through validation methods, we show that these models work well in many cases, even when predicting lower bounds for new categories of shapes, with low approximation error.
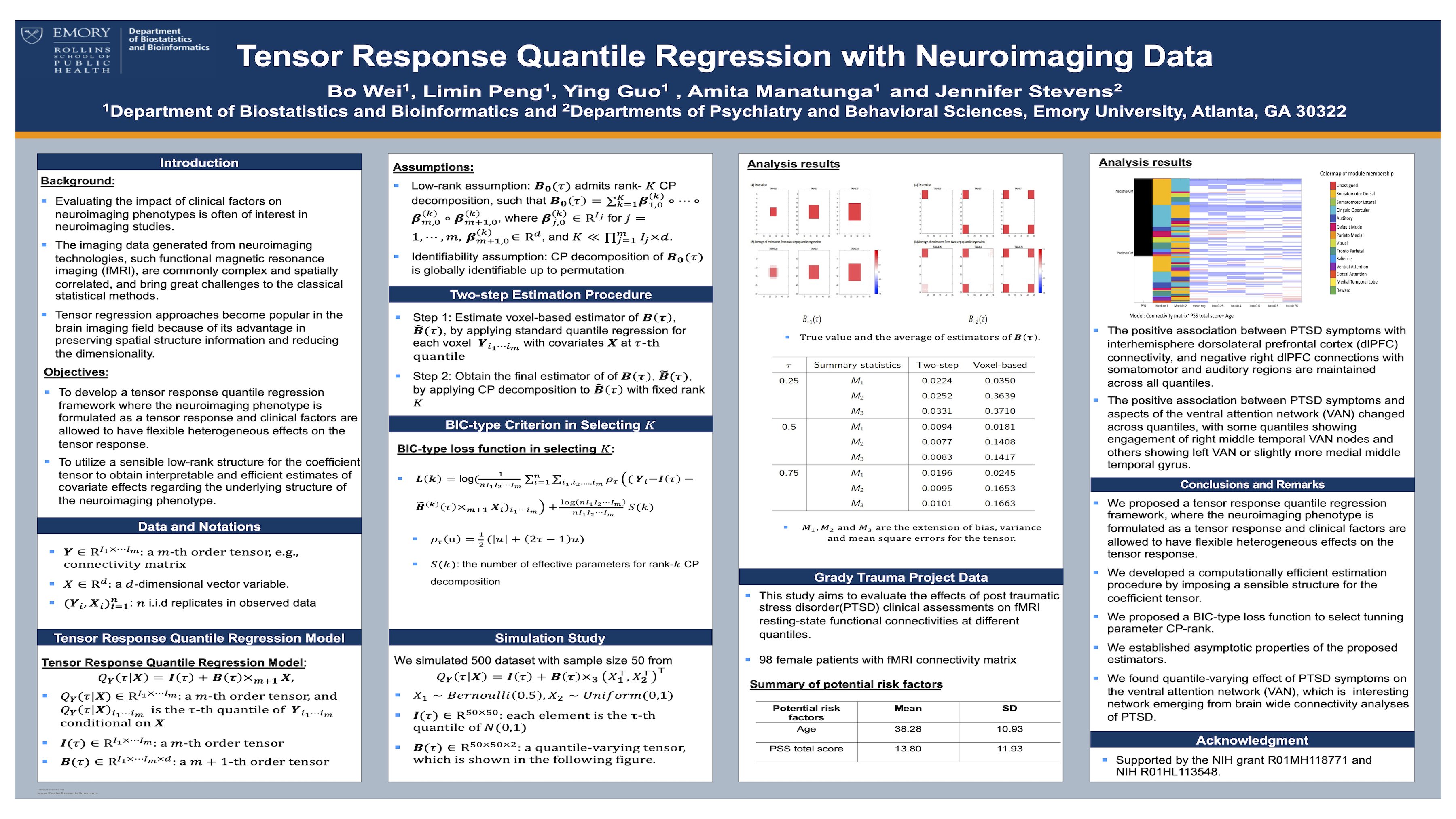
Poster 28. Tensor response quantile regression with neuroimaging data
Bo Wei
Emory University
Email: bwei8@emory.edu
Abstract: Evaluating the impact of clinical factors on neuroimaging phenotypes is often of interest in neuroimaging studies. To this end, we propose a tensor response quantile regression framework, where the neuroimaging phenotype is formulated as a tensor response and clinical factors are allowed to have flexible heterogeneous effects on the tensor response. We develop a computationally efficient estimation procedure for the regression coefficient tensor associated with the covariate effects by imposing a sensible low-rank structure for the coefficient tensor. This approach allows interpretable estimates of covariate effects regarding the underlying structure of the neuroimaging phenotype. We establish the asymptotic properties of the proposed estimators. Simulation studies demonstrate good finite-sample performance of the proposed method. We apply the proposed methods to investigate the association of post-traumatic stress disorder(PTSD) clinical assessments and fMRI resting-state functional connectivities in the Grady Trauma Project.
Poster 29. Multilevel hybrid principal components analysis for region-referenced multilevel functional EEG data
Emilie Campos
UCLA
Email: ejcampos@ucla.edu
Abstract: Electroencephalography (EEG) experiments produce region-referenced functional data representing brain signals collected across the scalp. The data typically also has a multilevel structure where the high-dimensional observations are collected across experimental conditions or multiple visits. Common analysis of EEG reduces the data complexity by collapsing the functional and regional dimensions, by analyzing specific event-related potential (ERP) features or specific frequency band power in a pre-specified scalp region. This practice can fail to portray the more comprehensive differences in the entire ERP signal or the power spectral density (PSD) across the entire scalp. The proposed multilevel hybrid principal components analysis (M-HPCA) utilizes dimension reduction tools from both vector and functional principal components analysis (based on weak separability of the high-dimensional covariance process) to decompose total variation into between and within subject components along both the functional and regional dimensions. The proposed approach enables computationally efficient estimation and inference through the use of a minorization-maximization (MM) algorithm to target model components coupled with a bootstrap procedure for inference. The diverse array of applications of M-HPCA is showcased with two real data examples. While ERP responses to match vs. mismatch conditions are compared in an audio odd-ball paradigm across typically developing (TD), minimally verbal and verbal children diagnosed with Autism Spectrum Disorders (ASD) in the first example, reliability of the PSD of ASD and TD children collected across visits that are only a week apart are compared in the second. Finite sample properties of the proposed methodology are studied in extensive simulations.
Indiana University Bloomington
Email: ddpham@iu.edu
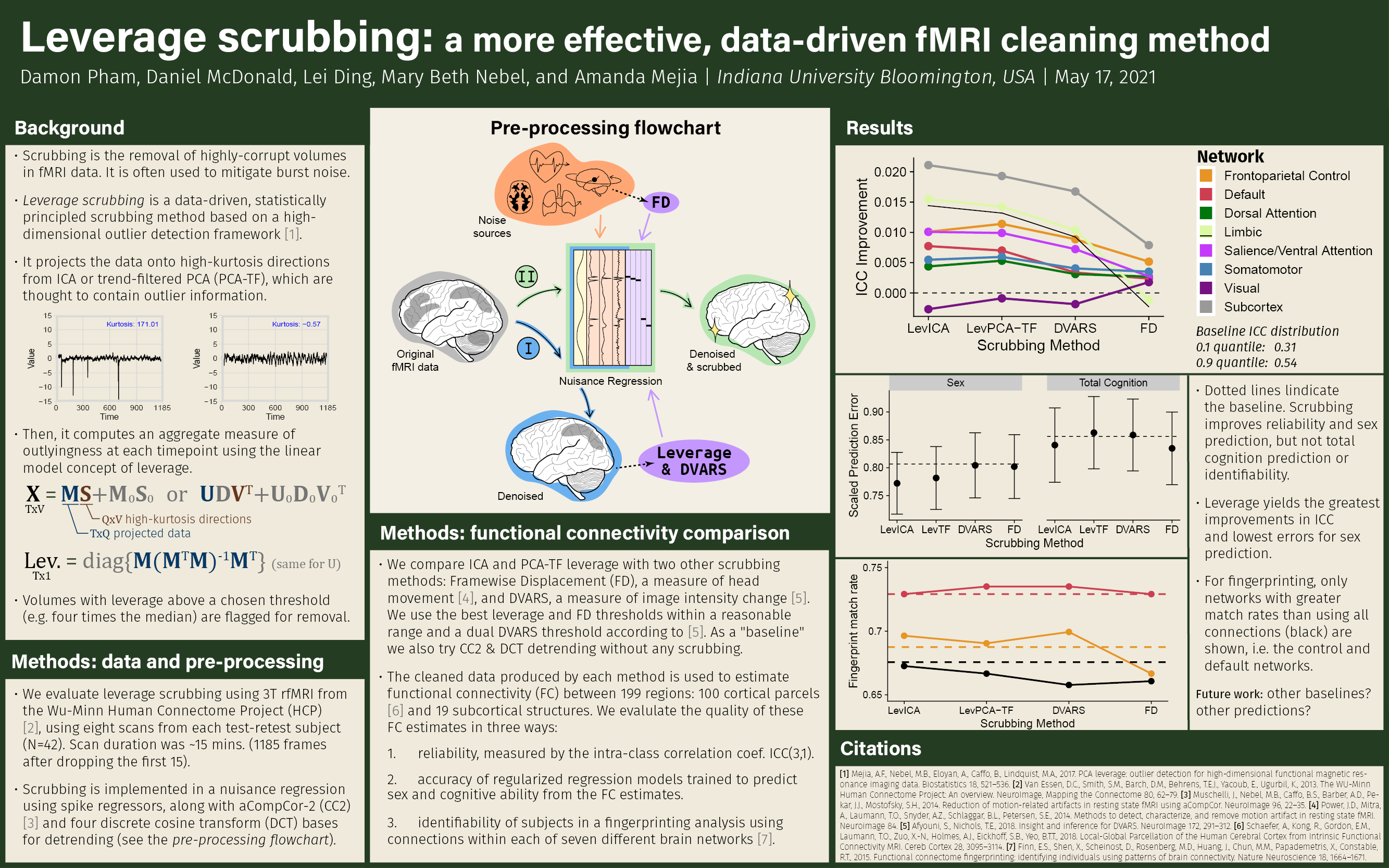
Abstract: Functional MRI data require careful pre-processing and denoising to reduce the effects of head motion, scanner drift, respiration, heartbeat, thermal noise, and other sources of non-neuronal variation. Denoising techniques typically fall into two categories: regression-based, which remove components varying across the entire scan (e.g. slow scanner drift), and scrubbing-based, which remove artifactual volumes (e.g. those concurrent with abrupt head movement). Motion scrubbing and DVARS are popular scrubbing techniques, but motion scrubbing only removes noise co-occurring with head motion, and DVARS only takes into account deviation from the previous frame. Leverage scrubbing is a statistically-principled, data-driven method for cleaning fMRI. It works by identifying directions in the data likely to express artifacts. These directions are estimated by first performing independent (or principal) component analysis, then retaining the components whose scores have kurtosis that statistically exceeds what would be expected under the null of no outliers. Volumes (time points) that have high scores associated with these retained components are likely to contain burst noise. We compute an overall leverage score (based on the regression concept) for each volume, which is thresholded to flag volumes for removal. Using test-retest data from the Human Connectome Project, we compare the performance of leverage scrubbing with two other scrubbing methods, framewise displacement (FD) and DVARS. For each method, we assess the reliability of functional connectivity (FC) estimates, the accuracy of predicting sex based on FC, and the identifiability of individual subjects based on their FC. We find evidence that leverage-based scrubbing clearly outperforms motion scrubbing based on all metrics. In general, leverage-based and DVARS-based scrubbing improves the reliability and sex-predictiveness of FC, but has little effect on their identifiability.
Poster 31. Harmonization of Functional Connectivity Reduces Scanner Effects in Community Detection
Andrew Chen
University of Pennsylvania
Email: andrewac@pennmedicine.upenn.edu
Abstract: Community detection on graphs constructed via functional magnetic resonance imaging (fMRI) scans has become an increasingly popular method for studying brain functional organization. Similar to other studies involving neuroimaging data, studies of brain community structure commonly acquire subjects on multiple scanners across different locations. Differences in scanner can introduce variability into the downstream results, often called scanner effects. These effects have been previously shown to significantly impact common metrics in brain network analyses. In this study, we identify substantial scanner effects in community detection results and relevant network metrics. We assess a known harmonization method and propose two additional methods for harmonization of functional connectivity. We demonstrate that our new methods perform well to remove scanner effects in community structure and related metrics at both the scanner and subject level.
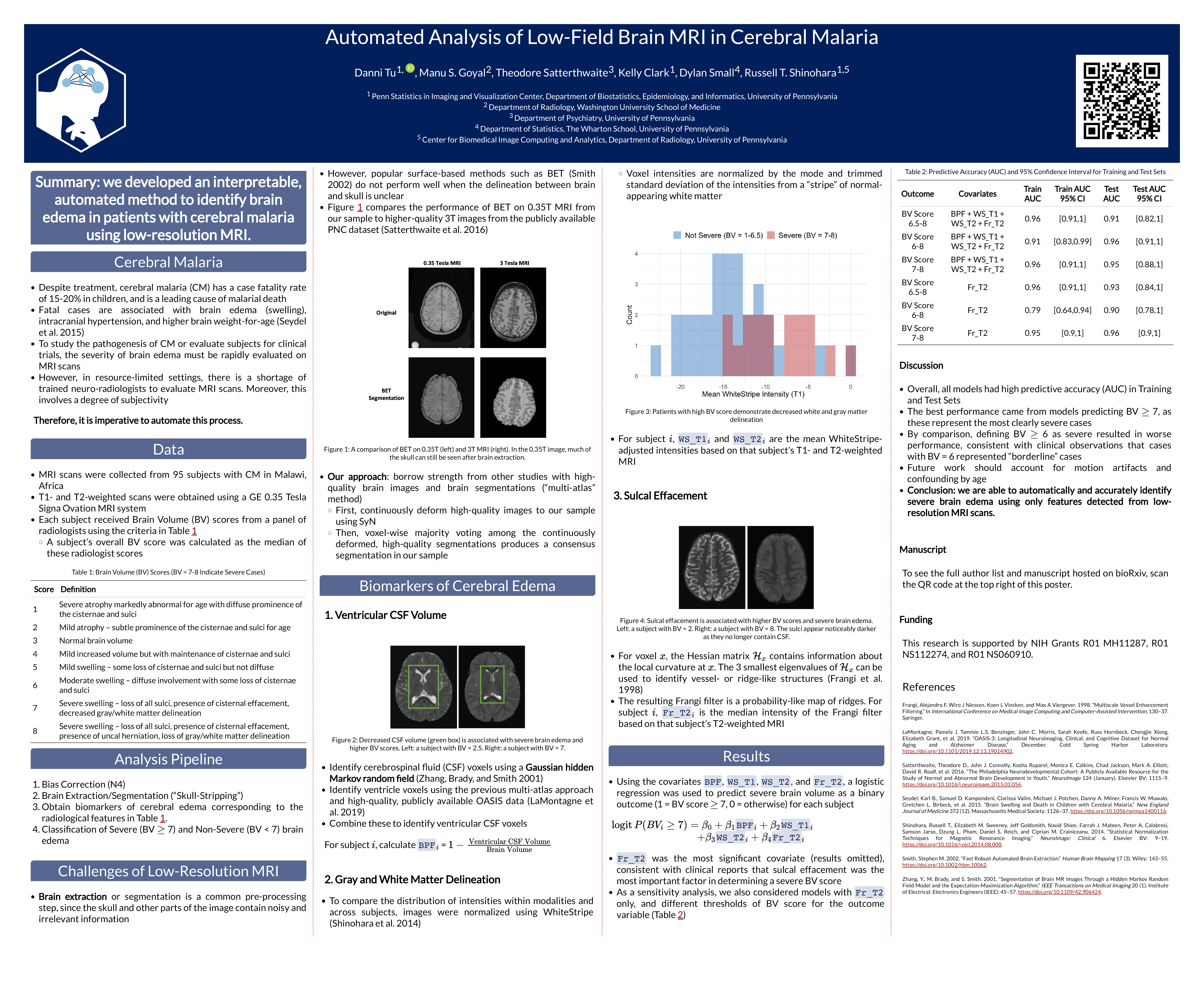
Poster 32. Automated Analysis of Low Field Brain MRI in Cerebral Malaria
Danni Tu
University of Pennsylvania
Email: danni.tu@pennmedicine.upenn.edu